뉴스데이터 예측 분류📰
2020/05~2020/06
여러가지 예측 분류 방법을 이용한 뉴스 데이터 참 거짓 예측

문제 인식
디지털 형태의 의사소통을 통해 전파되는 오보 등의 허위사실인 가짜 뉴스가 소셜 미디어를 통해 유통된 결과 큰 사회적 문제를 가져왔기 때문에 뉴스 데이터의 참 거짓을 분류하는 분석을 진행했습니다.
프로젝트 구조
- 데이터 전처리
- 분류 분석
- Logistic Regression Classifier
- Support Vector Classifier
- Multinomial Naive Bayes Classifier
- Bernoulli Naive Bayes Classifier
- Gradient Boost Classifier
- XGBoost Classifier
- Decision Tree
- Random Forest Classifier
- KNN Classifier
- 모델 평가
- 결론
사용한 데이터
1. 데이터 전처리(클리닝)
- 영문자 이외 문자 공백으로 전환
- 소문자 변환
- 불용어 제거
- 공백으로 구분된 문자열로 결합하여 결과 반환
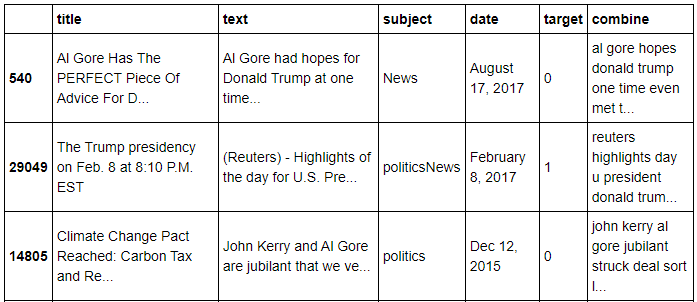
2. 분류 분석
연속적인 함수를 실행시킬 수 있는 pipeline을 이용해 combine컬럼을 벡터화 시킨후, 역문서 빈도를 적용하고, 모델을 적용하였습니다.
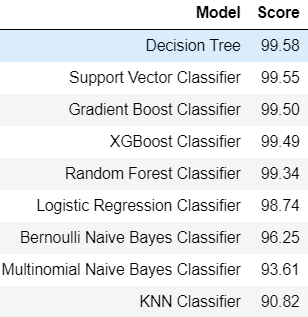
Decision Tree 모델의 정확도가 가장 높게 나왔습니다.
3. Decision Tree 평가
- 훈련용 모델은 99.91%이고, 테스트용 모델은 99.58%로 큰 차이를 보이지 않아서 과대적합이 아닌 것을 알 수 있습니다.
- 잘못 분류된 데이터가 적은 것으로 보아 모델이 잘 작동하고 있습니다.
- 과적합 확인
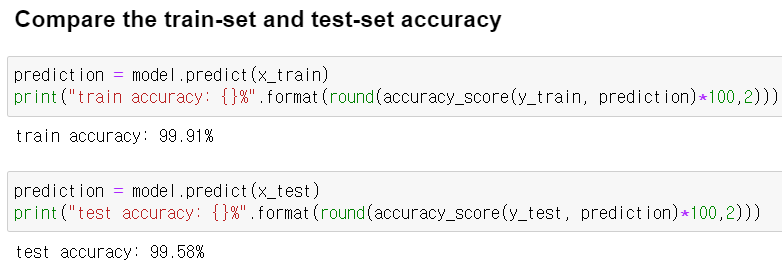
- 데이터 적용 평가

4. 결론
분석 결과 의사결정나무를 이용한 분류 모델의 정확도가 가장 높았기 때문에 의사결정나무 모델을 선정했습니다.
모델의 과적합을 확인한 결과 훈련용 모델과 테스트용 모델의 정확도가 비슷했기 때문에 과적합이 아님을 확인할 수 있었고, confusion matrix를 이용하여 확인해본 결과 뉴스 진짜 뉴스와
가짜 뉴스를 잘 분류하고 있음을 확인할 수 있었습니다.
뉴스 분류 분석 프로젝트를 통하여 자연어 처리에 대해서 공부할 수 있었고, 여러 가지 분류 모델에 대해서 공부할 수 있었습니다.