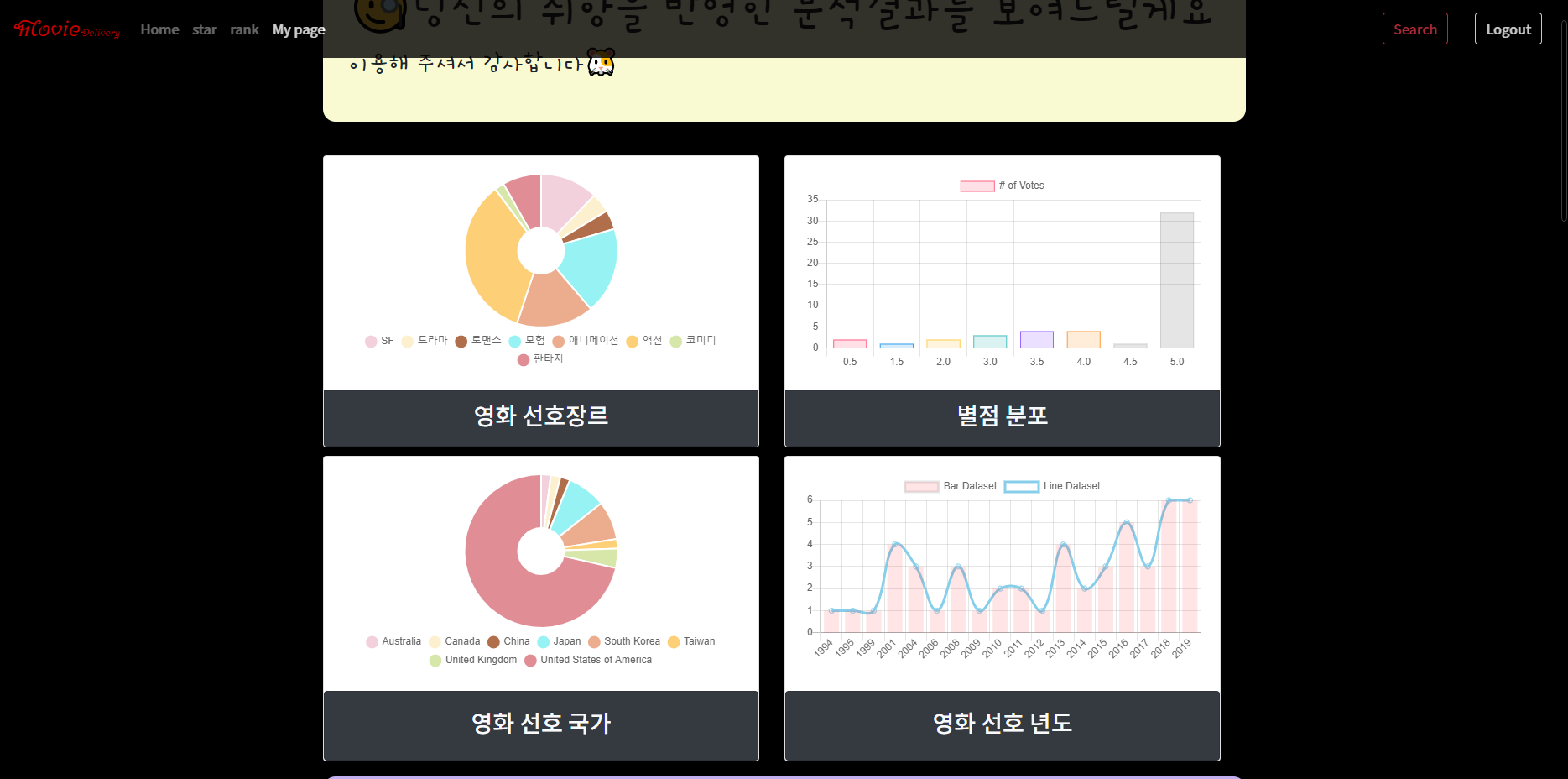
영화 추천 시스템🎞
2020/03~2020/08
[site 가입하지 않고 둘러보기]
id: hello@naver.com /
password: hello
사용자가 평가한 영화 평점과 다른 사용자의 영화평점간의 유사도를 비교하여 유사도가 높은 사용자가 높게 평가한 영화를 사용자에게 추천해주는 사용자 기반 협업 필터링을 이용하여 추천 시스템을 구현하였습니다.

작품 배경 및 필요성
- 추천 시스템은 사용자의 취향을 파악해 취향에 따라 아이템을 추천해 줌으로써 사용자가 해당 아이템을 구매할 확률이 높아집니다.
- 높은 신뢰도의 추천 시스템을 경험한 사용자는 높은 확률로 충성고객이 될 수 있습니다.
프로젝트 구조
- 탐색적 데이터 분석
- 모델링
- 모델 평가 및 결론
- 활용방안 - 웹사이트
사용한 데이터
- tmdb open api
- 웹페이지 구현에 이용
- MovieLens Latest Datasets
- links로 합쳐서 tmdbid를 가져와서 사용
- mongodb에 저장후 비교할 사용자 데이터로 이용
1. 탐색적 데이터 분석(EDA)
- 유저 평점 분포
- 영화 년도 분포
- 영화 장르 분포
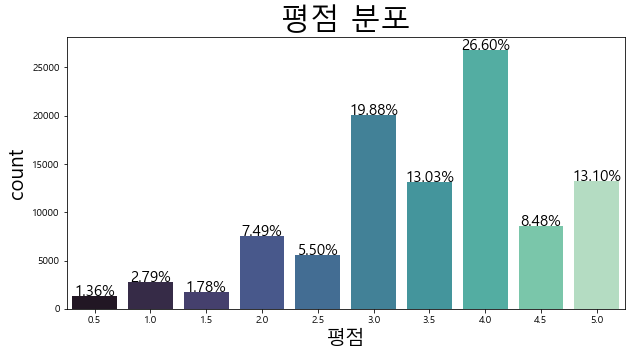
유저가 가장 많이 준 평점은 4.0이고 2.0이하의 낮은 점수는 낮은 분포를 보였습니다.
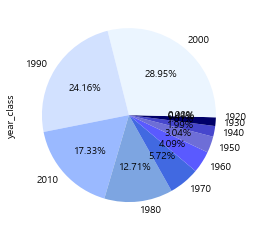
1920년대부터 2010년대까지의 영화로 구성되어 있습니다. 영화 추천 시에 사용할 수 있는 데이터의 크기가 한정되기 때문에 1990~2010년까지의 영화 데이터만 사용했습니다.
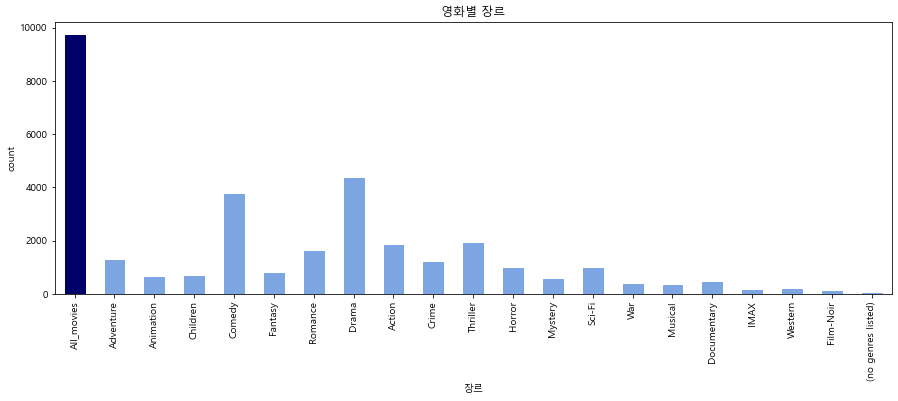
드라마 장르와 코미디 장르가 가장 많은 수를 보였습니다.
2. 모델링
- 먼저 사용자 데이터를 피벗테이블로 변형했습니다.
- 조합 가능한 모든 사용자를 하나씩 대입해 보는 방식으로 유사도가 높은 사용자를 구했습니다.
- 유사도가 높은 사용자들이 평점을 준 영화를 사용자에게 추천해 주고 그 영화에 대한 예상 점수를 출력했습니다.
3. 모델 평가 및 결론
- 유클리디언 거리와 코사인 거리 측정 방법을 이용하여 두 벡터 간의 유사도를 측정한 결과 유클리디언 거리를 이용한 모델의 MAE 점수와 RMSE 점수가 더 낮으므로 유클리디언 거리를 이용한 모델을 사용하여 웹을 구현했습니다.
- 대부분의 사람들이 선호하는 영화는 액션, 스릴러 등으로 로맨스를 좋아하는 유저들에게는 좋은 결과를 내지 못할수 있습니다. 유저가 골고루 분포된 데이터를 사용하면 좀더 좋은 결과를 낼 수 있을 것입니다.

4. 활용방안 - 웹사이트